

CMEDIA: The Library of Congress (LoC)’s crowdsourcing program, reportedly By the People, permits volunteers to transcribe, review, and tag digitized pages from the Library’s collections.
Apart from this, once those transcriptions are completed,they released to the Library’s website, where they help make items more accessible and discoverable.
In addition to those transcriptions, By the People also produces and releases datasets of completed transcriptions to the Library’s website
To date, LoC’s website contains19 By the People datasets in the Selected Datasets Collection, and with more transcription campaigns completed by volunteers, that number will continue to grow.
Each available dataset package consists of a .CSV file containing data exported from Concordia (the software behind By the People) as well as a README providing information about the structure of the dataset and transcription campaign.
All the transcriptions and tags that were created by volunteers, are included in the .CSV file, which opens up the possibility for computational research across collections with By the People transcriptions.
The LoC has just created the resource for all. For example, datasets from four campaigns have been used by the Library staff to create Python tutorial for using By the People with materials related to the women’s suffrage movement (from the Susan B. Anthony Papers, Carrie Chapman Catt Papers, Elizabeth Cady Stanton Papers, and Mary Church Terrell Papers) to experiment with Natural Language Processing and create simple visualizations.
Organized in a series of Jupyter Notebooks (the notebooks, themselves are available through GitHub), the tutorial uses the spaCy Python library to break down and analyze the transcriptions using Natural Language Processing techniques.
There are two visualizations, the first charting word frequency for each dataset, and the second charting word frequency for the speeches in the Susan B. Anthony papers.
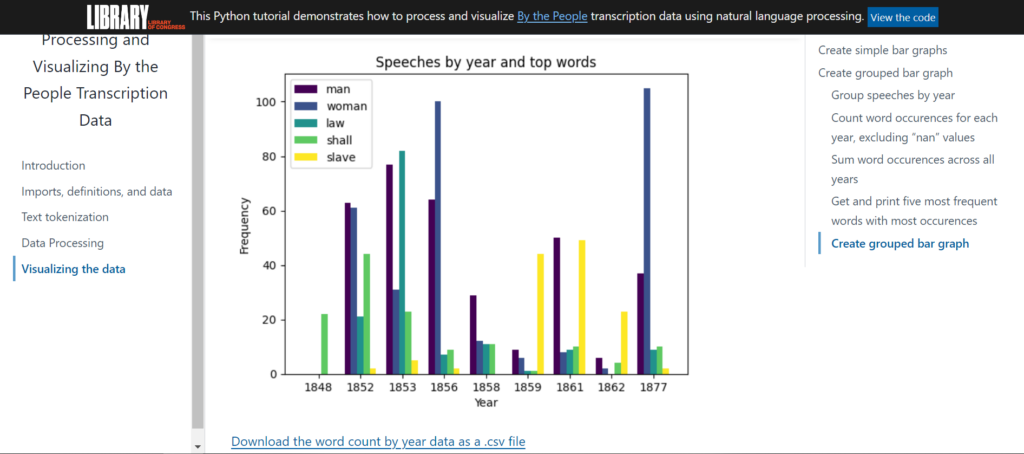
These four datasets are being utilized by the code, but could be applied to other By the People datasets as well.
The data processing techniques presented in this tutorial could also be used as a starting point for other visualizations or analytical work. Students at the University of Michigan School of Information experimented with data from the Branch Rickey papers.
Library staff and interns also created At the table with: Mary Church Terrell project


